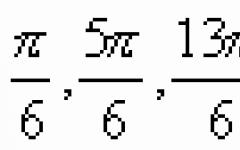
Związki ekonometrii z innymi dyscyplinami. Jaka jest specyfika syntezy teorii ekonomii i ekonometrii? Ekonometria, bazując na obiektywnie istniejących prawach ekonomicznych, które w teorii ekonomii są definiowane jakościowo, na poziomie pojęciowym, tworzy podejścia do ich formalizacji i ilościowego wyrażania powiązań pomiędzy wskaźnikami ekonomicznymi.
Statystyka gospodarcza dostarcza ekonometrii metod generowania niezbędnych wskaźników ekonomicznych, metod ich selekcji, pomiaru itp.
Narzędzia matematyczne i statystyczne rozwinięte w ekonometrii wykorzystują i rozwijają takie gałęzie statystyki matematycznej, jak modele regresji liniowej, analiza szeregów czasowych i konstrukcja układów równań równoczesnych.
To właśnie oparcie teorii ekonomii na konkretną statystykę ekonomiczną i wydobycie z tego lądowania, przy pomocy odpowiedniego aparatu matematycznego, dobrze określonych zależności ilościowych, stanowi kluczowy punkt zrozumienia istoty ekonometrii, odróżniającej ją od ekonomii matematycznej , statystyka opisowa i statystyka matematyczna. Zatem ekonomia matematyczna jest matematycznie sformułowaną teorią ekonomii, która bada relacje między zmiennymi ekonomicznymi na poziomie ogólnym (nieilościowym). Staje się ekonometrią, gdy symbolicznie reprezentowane w tych zależnościach współczynniki zastępuje się konkretnymi szacunkami liczbowymi wyprowadzonymi z konkretnych danych ekonomicznych.
Etapy budowy modelu ekonometrycznego. Głównym celem ekonometrii jest modelowy opis określonych zależności ilościowych zachodzących pomiędzy analizowanymi wskaźnikami w badanym zjawisku społeczno-gospodarczym.
Wśród stosowane cele można wyróżnić trzy:
- prognoza wskaźniki (zmienne) ekonomiczne i społeczno-ekonomiczne charakteryzujące stan i rozwój analizowanego systemu;
- imitacja różne możliwe scenariusze rozwoju społeczno-gospodarczego analizowanego systemu, gdy statystycznie zidentyfikowane zostaną zależności pomiędzy charakterystykami produkcji, konsumpcji, polityki społecznej, finansowej itp. służą do prześledzenia, jak planowane (możliwe) zmiany niektórych kontrolowanych parametrów produkcji lub dystrybucji wpłyną na interesujące nas wartości „wyjściowych” cech;
- analiza mechanizm powstawania i stan analizowanego zjawiska społeczno-gospodarczego. Jak działa mechanizm generowania dochodu gospodarstwa domowego Czy rzeczywiście istnieje dyskryminacja płacowa kobiet i mężczyzn i jak duża jest ona? Znajomość rzeczywistych zależności ilościowych w badanym zjawisku pozwoli lepiej zrozumieć konsekwencje podjętych decyzji, przeprowadzanych reform gospodarczych i skorygować je w czasie.
Według poziomu hierarchia analizowanego systemu gospodarczego poziom makro(czyli cały kraj), poziom mezo(regiony, branże, korporacje), poziom mikro(rodziny, przedsiębiorstwa, firmy).
Profil badania ekonometryczne określają problemy, na których się koncentrują: polityka inwestycyjna, finansowa, społeczna, stosunki dystrybucyjne, ceny itp. Im bardziej szczegółowo zdefiniowany jest profil badań, tym trafniejsza jest wybrana metoda i z reguły skuteczniejszy wynik.
Jedną z podstawowych koncepcji ekonomii jest związek między zjawiskami gospodarczymi, a co za tym idzie, cechami (zmiennymi), które je charakteryzują. Popyt na jakieś dobro na rynku jest funkcją ceny; wydatki konsumpcyjne rodziny są funkcją jej dochodów itp., koszt produkcji zależy od wydajności pracy. We wszystkich tych przykładach jedna ze zmiennych (czynników) pełni rolę wyjaśniającej (wynikowej), a druga rolę wyjaśniającej (czynnika).
Proces modelowania ekonometrycznego można podzielić na sześć głównych etapów.
1. Inscenizacja. Na tym etapie formułowany jest cel badania i ustalany jest zbiór zmiennych ekonomicznych uczestniczących w modelu. Celem badań ekonometrycznych może być:
· analiza badanego obiektu gospodarczego;
· prognozę jego wskaźników ekonomicznych;
· analiza możliwego rozwoju procesu dla różnych wartości zmiennych niezależnych itp.
2. Z góry. Jest to przedmodelowa analiza istoty ekonomicznej badanego zjawiska, tworzenie i formalizacja informacji apriorycznych, w szczególności związanych z naturą i genezą wyjściowych danych statystycznych oraz losowych składników rezydualnych.
3. Parametryzacja. Realizowane jest modelowanie rzeczywiste, tj. wybór ogólnej formy modelu, w tym składu i formy zawartych w nim połączeń.
4. Informacyjne. Zbierane są niezbędne informacje statystyczne tj. rejestracja wartości czynników i wskaźników uczestniczących w modelu.
5. Identyfikacja modelu. Przeprowadzana jest analiza statystyczna modelu, a przede wszystkim statystyczna ocena nieznanych parametrów modelu.
6. Weryfikacja modelu. Sprawdzana jest adekwatność modelu; określa się, jak skutecznie rozwiązano problemy specyfikacji, identyfikacji i identyfikowalności modelu; przeprowadza się porównanie danych rzeczywistych i modelowych oraz ocenia się dokładność danych modelowych.
Ostatnim trzem etapom (4, 5, 6) towarzyszy niezwykle pracochłonna procedura kalibracji modelu, która polega na wypróbowaniu dużej liczby opcji obliczeniowych w celu uzyskania wspólnego, spójnego i identyfikowalnego modelu.
Rzeczywisty model matematyczny badanego zjawiska można sformułować na poziomie ogólnym, bez dopasowywania do konkretnych danych statystycznych, tj. może to mieć sens bez etapów 4 i 5. Jednak w tym przypadku nie jest to kwestia ekonometryczna. Istota modelu ekonometrycznego polega na tym, że przedstawiany jako zbiór zależności matematycznych opisuje funkcjonowanie konkretnego systemu gospodarczego, a nie systemu w ogóle. Jest zatem „dostosowany” do pracy z konkretnymi danymi statystycznymi i dlatego umożliwia realizację IV i V etapu modelowania.
4. Baza statystyczna modeli ekonometrycznych. Jednym z najważniejszych etapów budowy modeli ekonometrycznych jest gromadzenie, agregacja i klasyfikacja danych statystycznych.
Główną podstawą badań ekonometrycznych są oficjalne statystyki lub dane księgowe, które stanowią punkt wyjścia wszelkich badań ekonometrycznych.
Modelując procesy gospodarcze wykorzystuje się trzy rodzaje danych:
1) dane przestrzenne (strukturalne), czyli zbiór wskaźników zmiennych ekonomicznych uzyskanych w określonym momencie (wycinek przestrzenny). Należą do nich dane dotyczące wielkości produkcji, liczby pracowników, dochodów różnych firm w tym samym momencie;
2) dane czasowe charakteryzujące ten sam przedmiot badań w różnych momentach (przedział czasowy), np. dane kwartalne o inflacji, przeciętnym wynagrodzeniu itp.;
3) dane panelowe (przestrzenno-czasowe), zajmujące pozycję pośrednią i odzwierciedlające obserwacje dużej liczby obiektów i wskaźników w różnych momentach. Należą do nich: wyniki finansowe kilku dużych funduszy inwestycyjnych w ciągu kilku miesięcy; wysokość podatków płaconych przez koncerny naftowe w ciągu ostatnich kilku lat itp.
Zebrane dane można przedstawić w formie tabel, wykresów i wykresów.
5. Główne typy modeli ekonometrycznych. W zależności od dostępnych danych i celów modelowania w ekonometrii wyróżnia się trzy klasy modeli.
Modele regresji jednorównaniowej. Regresja Zwyczajowo nazywa się zależność średniej wartości wielkości (y) od innej wielkości lub od kilku wielkości (x i).
W takich modelach zmienna zależna (objaśniona) jest reprezentowana jako funkcja, gdzie są zmienne niezależne (objaśniające), a są to parametry. W zależności od liczby czynników zawartych w równaniu regresji zwyczajowo rozróżnia się regresję prostą (sparowaną) i regresję wielokrotną.
Regresja prosta (parami). to model, w którym średnią wartość zmiennej zależnej (objaśnionej) y rozważa się jako funkcję jednej zmiennej niezależnej (objaśniającej) x. W domyśle regresja parami jest modelem postaci:
Wyraźnie:
gdzie aib są szacunkami współczynników regresji.
Regresja wielokrotna to model, w którym średnią wartość zmiennej zależnej (objaśnionej) y rozważa się jako funkcję kilku zmiennych niezależnych (objaśniających) x 1, x 2, ... x n. W domyśle regresja parami jest modelem postaci:
![]() .
.
Wyraźnie:
gdzie aib 1, b 2, b n są szacunkami współczynników regresji.
Przykładem takiego modelu jest uzależnienie wynagrodzenia pracownika od jego wieku, wykształcenia, kwalifikacji, stażu pracy, branży itp.
Ze względu na formę uzależnienia wyróżnia się:
· regresja liniowa;
· regresja nieliniowa, która zakłada istnienie nieliniowych zależności pomiędzy czynnikami wyrażonych odpowiednią funkcją nieliniową. Często modele o nieliniowym wyglądzie można sprowadzić do postaci liniowej, co pozwala na zaklasyfikowanie ich jako liniowe.
Można na przykład badać płace jako funkcję cech społeczno-demograficznych i kwalifikacji pracownika.
UDC: 336 BBK: 65,05
ZASTOSOWANIE NARZĘDZI EKONOMETRII DO FORMOWANIA WIELOCZYNNIKOWEGO KRYTERIA OCENY Spełnialności Organizacji
Suvorova L.V., Suvorova T.E., Kuklina M.V.
WYKORZYSTANIE NARZĘDZI EKONOMETRII DO KSZTAŁCENIA
WIELOCZYNNIKOWE KRYTERIA OCENY TRWAŁOŚCI ORGANIZACJI
Słowa kluczowe: spółka, prawdopodobieństwo, upadłość, prawdopodobieństwo upadłości, ekonometria, ocena wypłacalności, integralne kryterium oceny, model, ocena, kryterium, prognozowane prawdopodobieństwo.
Słowa kluczowe: przedsiębiorstwo, prawdopodobieństwo, upadłość, prawdopodobieństwo upadłości, ekonometria, ocena żywotności, integralne kryterium oceny, model, wycena, kryterium, prognozowane prawdopodobieństwo.
Streszczenie: w artykule omówiono możliwość wykorzystania narzędzi ekonometrycznych do stworzenia wieloczynnikowego kryterium oceny żywotności organizacji. Model oceny, wygenerowany metodą analizy hierarchicznej, testowany jest na danych stu rosyjskich spółek niefinansowych, uzyskane wyniki porównywane są z wyjściowymi parametrami modelu, po czym wyciąga się wniosek o jego praktycznej przydatności.
Streszczenie: w artykule omówiono możliwość wykorzystania narzędzi ekonometrycznych do formułowania wieloczynnikowych kryteriów oceny żywotności organizacji. Model oceny, tworzony w procesie hierarchii analitycznej, jest testowany na danych setek rosyjskich firm niefinansowych; wyniki te porównuje się z początkowymi parametrami modelu, a następnie stwierdza się jego praktyczną przydatność.
W obliczu pogarszającej się sytuacji gospodarczej zarówno w kraju, jak i poza jego granicami, wiele firm boryka się z trudnościami finansowymi. Upadłość organizacji jako podmiotu stosunków gospodarczych może stać się przedmiotem postępowania sądowego. Tym samym współcześni menedżerowie finansowi stają przed zadaniem nie tylko zapobiegania zjawiskom kryzysowym i zapewnienia stabilnej sytuacji finansowej swojego przedsiębiorstwa, ale także udowodnienia jego żywotności osobom trzecim.
Obecnie istnieje sporo wieloczynnikowych kryteriów oceny rentowności przedsiębiorstw, proponowanych przez różnych autorów, zarówno krajowych, jak i zagranicznych (naukowcy E. Altman, R. Taffler i G. Tishaw, R. Lis, R.S. Saifulin i G.G. Kadykov ). Państwowej Akademii Ekonomicznej w Irkucku, O.P. Zaitseva, U. Beaver, J. Kon-
nan i M. Golder, D. Fulmer, G. Springgate). Należy zauważyć, że modele zagraniczne nie zawsze są akceptowalne dla organizacji rosyjskich, ponieważ wykorzystują one stałe współczynniki obliczone zgodnie z innymi warunkami ekonomicznymi, cechami kredytów i podatków.
Diagnozę czynników prowadzących organizację do upadłości można przeprowadzić różnymi metodami, w tym metodami analitycznymi, eksperckimi, programowania liniowego i dynamicznego, a także z wykorzystaniem modeli symulacyjnych.
Celem pracy jest przetestowanie nowego modelu oceny rentowności przedsiębiorstw z wykorzystaniem narzędzi ekonometrycznych.
W oparciu o metodę analizy hierarchii opracowaliśmy nowy model oceny i ustalania żywotności organizacji
Wartość progową wskaźnika całkującego 1 określa się:
X = 0,194*P(12) + 0,186*P(15) + 0,19*P(27) + 0,232*P(30) + 0,197*P(33),
P(12) - stopień wypłacalności organizacji;
P(15) - stosunek prądu;
P(27) - zwrot z kapitału obrotowego;
P(30) - produktywność kapitału;
P(33) - zwrot ze sprzedaży
Metoda analizy hierarchicznej jest techniką oceny wielokryterialnej, za pomocą której dobierane są czynniki wskaźnikowe i tworzony jest model wieloczynnikowy. W celu znalezienia priorytetowych wskaźników-czynników wykorzystano skalę względnej ważności T. Saaty'ego i K. Kearnsa2. Za jej pomocą skonstruowano macierz porównań parami wskaźników-czynników i dokonano wyboru lokalnych priorytetów.
Za najwyższy priorytet wśród branych pod uwagę czynników uznano: stopień wypłacalności, wskaźnik płynności bieżącej, zwrot z kapitału obrotowego, produktywność kapitału oraz rentowność sprzedaży.
Na potrzeby dalszych badań skorygowano wartości priorytetów wybranych czynników, dzieląc ich wartości początkowe przez sumę tych ostatnich, uzyskując w ten sposób znormalizowany wektor priorytetów dla okrojonego zbioru kryteriów.
Wartość progową wyznaczono na podstawie analizy empirycznej na danych rzeczywistych. Utworzono próbę 100 niefinansowych przedsiębiorstw rosyjskich
Suvorova L.V., Suvorova T.E., Kuklina M.V.
Korzystając z bazy danych, w próbie znalazło się 50 firm zamożnych i 50 firm, które sąd ogłosił upadłość. Dla każdej organizacji obliczono wskaźnik integralny i skonstruowano wykres zależności wskaźnika całkowego od stanu przedsiębiorstw.
W ramach opracowanego przez nas modelu niewypłacalne okazały się spółki, których wskaźnik całkowy nie przekraczał 15.
Do oceny zależności pomiędzy prawdopodobieństwem upadłości organizacji a wartością kryterium integralnego wykorzystano narzędzia ekonometryczne. W tym celu wykorzystano tę samą próbę 100 niefinansowych firm rosyjskich.
Przetestowano binarne modele wyboru: model Probka4 (kumulatywna funkcja standardowego rozkładu normalnego) i Logit-model (skumulowana funkcja prawdopodobieństwa rozkładu logistycznego). Modele binarne umożliwiają określenie zależności pomiędzy prawdopodobieństwem upadłości przedsiębiorstwa a wartością kryterium całkowego.
Według modeli tego typu zmienna zależna przyjmuje dwie wartości: 0 i 1. Jako zmienną zależną wybraliśmy stan przedsiębiorstwa. Firmie wypłacalnej przypisuje się wartość „0”, a firmie niewypłacalnej wartość „1”. W wygenerowanej próbie liczba spółek wypłacalnych i niewypłacalnych pokrywa się i wynosi 50.
Wszystkie obliczone współczynniki, w tym wskaźnik całkowy dla wybranych spółek, przedstawiono w tabeli 1.
1 Suvorova, L.V., Suvorova, T.E. Ocena niewypłacalności organizacji metodą analizy hierarchicznej // Materiały VIII Międzynarodowej Konferencji Naukowo-Praktycznej „Infrastrukturalne sektory gospodarki: problemy i perspektywy rozwoju”. - Nowosybirsk: NSTU, 2015.
2 Makarow, A.S. O problemie wyboru kryteriów analizy żywotności organizacji // Analiza ekonomiczna: teoria i praktyka. 2008. Nr 3.
3 FIRA PRO - System informacyjno-analityczny, pierwsza niezależna agencja ratingowa [Zasoby elektroniczne]. - Adres URL: http://www.fira.ru/. - Czapka z ekranu
4 Sandor, Zolt. Edukacja ekonometryczna: ograniczone zmienne zależne. Wielomianowe modele dyskretnego wyboru // Kwantyl. - 2009. -№7. - s. 9-20.
Firma Wskaźnik-czynnik Kryterium integralne Y: 1- firma niewypłacalna 0- firma bogata
Produktywność kapitału, udziały Wskaźnik płynności bieżącej, udziały Stopień wypłacalności zobowiązań bieżących, udziały Rentowność kapitału obrotowego, % Rentowność sprzedaży, %
1 10,82 1,97 3,28 47,66 40 20,48 0
2 1,68 1,17 14,69 65,88 50 25,88 0
3 7,4 3,24 4,64 79,75 100 38,15 0
4 18,08 3,8 4,2 8,37 100 27,05 0
5 6,01 1,08 4,24 23,77 100 26,69 0
50 1,11 20,76 0,62 96,63 100 42,40 0
51 3,52 5,32 0,45 0,43 8,7 3,69 1
52 1,85 0,1 66,96 0,78 2,2 14,03 1
59 1,65 0,91 74,25 115 3,3 37,52 1
66 0,1 1 77,45 1 10 17,41 1
99 3,38 0,024 38,03 -1,47 -2,4 7,41 1
100 0,38 0,05 2,25 1,42 9,6 2,70 1
Przetestowano dwa modele regresji, a wyniki testowania modeli przedstawiono za pomocą programu Eviews. Ustępuje w tabeli 2.
Tabela 2 – Testowanie modelu
Parametry modelu
Liczba obserwacji 100 100
Wskaźnik całkowy -0,149***(0,043) -0,338**(0,138)
Stała 2,391***(0,569) 5,155***(1,858)
Prob(statystyka LR) 0,000 0,000
McFadden R-kwadrat 0,769 0,804
Notatka. Błędy standardowe wskazano w nawiasach, poziomy istotności oznaczono gwiazdkami: *str<0,1; **p <0,05; ***p <0,01.
Na podstawie uzyskanych wyników stwierdzono, że obie regresje były na ogół istotne na poziomie 1%. Istotne są także szacunki współczynników na poziomie 1% dla modelu Probit i 5% dla modelu Logit. Oszacowanie współczynnika przed zmienną odpowiedzialną za wartość wskaźnika całkowego,
negatywny. Sugeruje to, że im wyższa wartość wskaźnika całkowego, tym mniejsze prawdopodobieństwo bankructwa.
Uzyskane wyniki oceny regresji można przedstawić w następującej postaci:
Рг = 2,391 - 0,149 * x()
Pi =L (5,155 - 0,338 * xt)
Zależność wartości wskaźnika całkowego od prawdopodobieństwa prognozy wyznaczonego za pomocą modeli Logit i Probit pokazano na rysunku 1. Można zastąpić
Chociaż oba modele dają niemal identyczne wyniki, nie obserwuje się znaczących różnic. Istnieje jednak jedno odchylenie od ogólnej dynamiki.
1-1-1-1-0 -,-■
♦ Model logitowy ♦ Model probitowy
Wartość wskaźnika całkującego
Rysunek 1 - Graficzne przedstawienie stosunku wartości kryterium całkowego
oraz ocenę prawdopodobieństwa upadłości
W celu określenia wartości progowej skonstruowano przewidywane prawdopodobieństwa upadłości dla wszystkich spółek z próby dla obu modeli binarnych. Na rysunkach 2 i 3 przedstawiono zależność prawdopodobieństwa prognozy od liczby obserwacji. Pierwsze 50 firm w próbie to firmy zamożne, a sąd ogłosił upadłość ostatnich 50 firm.
Wykresy te pokazują również, że istnieje jedno odchylenie. Spółka odpowiadająca numerowi 59 jest w istocie bankrutem, lecz kryterium integralne wskazywało na odwrotny wniosek. Dla tej spółki przewidywano bardzo niskie przewidywane prawdopodobieństwo upadłości.
Rysunek 2 – Graficzne przedstawienie stosunku przewidywanego prawdopodobieństwa upadłości do liczby spółek dla modelu Logit
Stwierdzono zatem, że jeżeli prognozowane prawdopodobieństwo upadłości przekracza 50%, spółka jest niewypłacalna. mniej niż 50%, wówczas firma jest
10 20 30 40 50 60 70 80 90 100
Rysunek 3 - Graficzne przedstawienie stosunku przewidywanego prawdopodobieństwa upadłości do liczby firm dla modelu Pshbk
Jak zauważono wcześniej, przy obliczaniu kryterium wieloczynnikowego za pomocą AHP popełniono dwie nieścisłości, a mianowicie, że 2 spółki posiadające prognozę wypłacalności są w rzeczywistości niewypłacalne. Odpowiada to błędowi I rodzaju. Podobna niedokładność wystąpiła przy przewidywaniu prawdopodobieństwa upadłości za pomocą narzędzi ekonometrycznych, jednak w tym przypadku był to błąd I rodzaju
herbata wyniosła 1% (tylko dla jednej niewypłacalnej spółki przewidywano niskie prawdopodobieństwo upadłości). W żadnym przypadku nie zaobserwowano błędu typu II. Moc wyjaśniająca modelu wynosi 100% minus błędy typu I i II. Obydwa utworzone modele, zarówno wykorzystujące AHP, jak i wykorzystujące narzędzia ekonometryczne, mają dużą moc objaśniającą (tab. 3).
Tabela 3 – Charakterystyka porównawcza narzędzi AHP i ekonometrii
Kryterium MAI Narzędzia ekonometrii
Próg X<15 - компания несостоятельна, Х>15 - firma jest bogata P<50% - компания состоятельна, Р >50% - firma jest niewypłacalna
Błąd I rodzaju (firma posiadająca prognozę wypłacalności jest niewypłacalna) 2% 1%
Błąd II rodzaju (spółka posiadająca prognozę niewypłacalności jest wypłacalna) 0% 0%
Moc wyjaśniająca modelu 98% 99%
Na podstawie wyników uzyskanych przy użyciu metody analitycznej możemy stwierdzić, że nowy model, hierarchia i przetestowane zastosowanie
narzędzia ekonometryczne są kluczem do bankructwa rosyjskich firm. optymalne i nadające się do diagnostyki
LISTA BIBLIOGRAFICZNA
1. Makarov, A.S. O problemie wyboru kryteriów analizy żywotności organizacji // Analiza ekonomiczna: teoria i praktyka. - 2008. - nr 3.
2. Suvorova, L.V., Suvorova, T.E. Ocena niewypłacalności organizacji metodą analizy hierarchii // Materiały VIII Międzynarodowej Konferencji Naukowo-Praktycznej „Infrastruktura Sektorów Gospodarki: Problemy i Perspektywy Rozwoju”, NSTU, Nowosybirsk, 2015.
3. Sandor, Zolt. Edukacja ekonometryczna: ograniczone zmienne zależne. Wielomianowe modele dyskretnego wyboru // Kwantyl. - 2009. - nr 7. - s. 9-20.
4. Altman, E. i Haldeman, R. (1977) Analiza ZETA: Nowy model identyfikacji ryzyka upadłości korporacji. Journal of Banking and Finance, 1, 29-35.
5. Beaver, W. (1966) Wskaźniki finansowe jako czynniki predykcyjne niepowodzenia. Journal of Accounting Research, 4,71-111.
6. Conan, J. i Holder, M. (1979) Explicatives zmienne wydajności i kontroli zarządzania, praca doktorska, CERG, Universite Paris Dauphine.
7. FIRA PRO - System informacyjno-analityczny, pierwsza niezależna agencja ratingowa [Zasoby elektroniczne]. - Adres URL: http://www.fira.ru/. - Czapka z ekranu
8. Fulmer, J. i Moon, J. (1984) Model klasyfikacji upadłości dla małych firm. Journal of kredytów banków komercyjnych, 25-37.
9. Springate, G. (1978) Przewidywanie możliwości niepowodzenia w kanadyjskiej firmie. Niepublikowane MBA Projekt badawczy, Uniwersytet Simona Frasera
1Przeprowadzono badanie możliwości matematycznych i statystycznych narzędzi ekonometrycznych, dzięki którym dokonano oceny i analizy ogólnej wydajności pracownika firmy. Jako wskaźnik wydajności pracowników wybrano wskaźnik zysku firmy stworzony przez pracownika. Określono główne wskaźniki dynamiki wydajności pracy i podano graficzną ilustrację wyników obliczeń. Zidentyfikowano kluczowe czynniki wpływające na wydajność pracownika firmy; w tym celu wykorzystano możliwości analizy korelacji i regresji z wykorzystaniem macierzy korelacji sparowanych. Przeprowadzono analizę sezonowego składnika wskaźnika efektywności pracowników. Dokonano obliczeń i analizy współczynników sprężystości charakteryzujących wpływ cech czynnika na efektywny wskaźnik efektywności pracy. Przeprowadzono analizę trendów kluczowych czynników. Skonstruowano równania regresji sparowanej i wielokrotnej. Jakość skonstruowanych równań regresji oceniano za pomocą kryteriów Fishera, statystyki t-Studenta i współczynnika determinacji. Przeprowadzono obliczenia punktowych i interwałowych prognoz wydajności pracownika firmy w okresach długoterminowych. Przedstawiono propozycje mające na celu poprawę efektywności pracowników firmy.
efektywność wydajności pracowników
analiza korelacji i regresji
ocena jakości regresji
1. Alekseeva E.V., Gusarova O.M. Ekonometryczne badanie wskaźników finansowych organizacji // Międzynarodowy studencki biuletyn naukowy. – 2016 r. – nr 4–4. – s. 497–500.
2. Golicheva N.D., Gusarova O.M. Teoria i praktyka modelowania procesów finansowych i gospodarczych w warunkach niepewności ekonomicznej. – Smoleńsk: Magenta, 2016. – 227 s.
3. Gusarova O.M. Analiza trendów priorytetowych kierunków gospodarki regionalnej // Badania Podstawowe. – 2016 r. – nr 8–1. – s. 123–128.
4. Gusarova O.M. Aparatura analityczna do modelowania zależności korelacyjno-regresyjnych // International Journal of Applied and Fundamental Research. – 2016 r. – nr 8–2. – s. 219–223.
5. Gusarova O.M., Kuzmenkova V.D. Modelowanie i analiza trendów rozwoju ekonomii regionalnej // Badania Podstawowe. – 2016 r. – nr 3–2. – s. 354–359.
6. Gusarova O.M. Analiza ekonometryczna zależności statystycznych między wskaźnikami rozwoju społeczno-gospodarczego Rosji // Badania podstawowe. – 2016 r. – nr 2–2. – s. 357–361.
7. Gusarova O.M. Metody i modele prognozowania działania systemów korporacyjnych // Teoretyczne i stosowane zagadnienia edukacji i nauki: zbiór prac naukowych na podstawie materiałów Międzynarodowej Konferencji Naukowo-Praktycznej, 2014. – s. 48–49.
8. Ilyin S.V., Gusarova O.M. Modelowanie ekonometryczne w ocenie zależności wskaźników regionalnych // Międzynarodowy Studencki Biuletyn Naukowy. – 2015 r. – nr 4–1. – s. 134–136.
9. Gusarova O.M. Monitorowanie kluczowych wskaźników efektywności procesów biznesowych // Aktualne zagadnienia ekonomii i zarządzania w modernizacji współczesnej Rosji. – Smoleńsk: Smolgortypografia, 2015. – s. 84–89.
10. Gusarova O.M. Modelowanie wyników biznesowych w zarządzaniu organizacją // Perspektywy rozwoju nauki i edukacji: zbiór prac naukowych na podstawie materiałów Międzynarodowej Konferencji Naukowo-Praktycznej, 2014. – s. 42–43.
11. Zhuravleva M.A., Gusarova O.M. Analiza i doskonalenie działalności spółek akcyjnych (na przykładzie OJSC Smolenskoblgaz) // Nowoczesne technologie naukochłonne. – 2014 r. – nr 7–3. – s. 10–12.
12. Gusarov A.I., Gusarova O.M. Zarządzanie ryzykiem finansowym banków regionalnych (na przykładzie OJSC Askold) // Nowoczesne technologie wymagające dużej wiedzy naukowej. – 2014 r. – nr 7–3. – s. 8–10.
13. Gusarova O.M. Badanie jakości krótkoterminowych modeli prognozowania wskaźników finansowych i ekonomicznych. – M., 1999. – 100 s.
14. Orlova I.V., Polovnikov V.A., Filonova E.S., Gusarova O.M. i inne. Podręcznik edukacyjno-metodyczny. – M.: 2010. – 123 s.
W celu zwiększenia efektywności firmy jako całości i każdego działu z osobna, a także przygotowania raportu analitycznego wyznaczającego strategiczną linię rozwoju, przeprowadzono badanie efektywności pracownika firmy. W trakcie badania, wykorzystując metody matematyczne i statystyczne, wykorzystując możliwości analizy korelacji i regresji, dokonano oceny pracy pracownika firmy Avtokholod LLC. Badane wskaźniki to: średni zysk firmy generowany przez indywidualnego pracownika (Y), zysk netto (X1), wolumen sprzedaży usług dla osób prawnych (X2), wolumen sprzedaży usług dla osób fizycznych (X3) , dodatkowy zysk w związku z poszerzeniem zakresu usług (X4).
Dynamikę badanych wskaźników zidentyfikowano za pomocą następujących wzorów (tab. 1). Ilustrację wyników obliczeń przedstawiono na rys. 1-2.
Tabela 1
Wskaźniki dynamiki znaków
|
Absolutny wzrost |
Tempo wzrostu |
Tempo wzrostu |
|
|
Podstawowy |
Na podstawie wyników graficznej interpretacji wyników obliczeń można stwierdzić, że w sprzedaży produktów spółki występuje czynnik sezonowy. Widać także wzrost zysku firmy, jaki przynosi pracownik w związku z poszerzeniem zakresu świadczonych usług.

Ryż. 1. Bezwzględny wzrost wydajności operacyjnej łańcucha

Ryż. 2. Bezwzględny podstawowy wzrost efektywności pracy pracowników
Doboru cech czynnikowych do budowy modeli regresji dokonano wykorzystując narzędzia matematyczne i statystyczne, wykorzystując możliwości korelacji i analizy regresji, wykorzystując macierz współczynników korelacji par (rys. 3).

Ryż. 3. Sparowana macierz korelacji
Analiza macierzy sparowanych korelacji pozwoliła na identyfikację czynnika wiodącego X2 (wielkość sprzedaży usług dla osób prawnych). Aby wyeliminować wieloliniowość, wykluczamy z uwzględnienia czynnik X3 (wielkość sprzedaży usług dla osób fizycznych). Wskazane jest również wyłączenie z rozważań czynnika X4 (dodatkowy zysk w wyniku poszerzenia zakresu usług) ze względu na niską korelację z wypadkowym atrybutem Y. Wyniki konstrukcji regresji wielokrotnej przedstawiono na rys. 4.

Ryż. 4. Wyniki analizy regresji
Na podstawie przeprowadzonych obliczeń równanie regresji wielokrotnej ma postać:
Y=0,871179777.Х1+ +0,919808093.Х2+152,4197205.
Oceńmy jakość otrzymanego równania regresji wielokrotnej: wartość współczynnika determinacji równa R = 0,964 jest dość bliska 1, zatem jakość otrzymanego równania regresji można uznać za wysoką; wartość kryterium Fishera F = 229,8248 przekracza wartość tabelaryczną 3,591, dlatego równanie regresji można uznać za statystycznie istotne i zastosować do oceny efektywności pracy pracownika firmy. Do oceny istotności statystycznej charakterystyk czynnikowych wykorzystuje się test t-Studenta. Za pomocą funkcji =STUDENT.REV.2Х(0,05;17) wyznacza się wartość tabeli t tabela = 2,109815578. Porównując obliczone wartości statystyki t, wzięte modulo, z tabelaryczną wartością tego kryterium, możemy wyciągnąć wniosek o statystycznej istotności czynników X1 i X2.
Ocenimy stopień wpływu czynników na atrybut efektywny za pomocą współczynników sprężystości, współczynników b i D (ryc. 5).

Ryż. 5. Obliczanie dodatkowych współczynników korelacji pomiędzy cechami
Częściowy współczynnik elastyczności pokazuje zmianę średniej wartości efektywnego wskaźnika, gdy średnia wartość atrybutu czynnika zmieni się o 1%, czyli przy wzroście zysku netto o 1% (X1) zysk firmy wzrośnie o 0,287 % (E1 = 0,287), przy wzroście o 1% wolumenu sprzedaży usług dla osób prawnych (X2), wolumen zysku wzrośnie o 0,535% (E2 = 0,535).
Współczynnik β pokazuje wielkość zmiany odchylenia standardowego wynikowej charakterystyki, gdy odchylenie standardowe charakterystyki czynnikowej zmienia się o 1 jednostkę, tj. wraz ze wzrostem o 1 jednostkę odchylenia standardowego zysku netto (X1) odchylenie standardowe wolumenu zysku wzrośnie o 0,304 (=0,304); wraz ze wzrostem o 1 jednostkę odchylenia standardowego wolumenu sprzedaży usług dla osób prawnych, odchylenie standardowe zysku organizacji wzrośnie o 0,727 jednostki (=0,727).
Δ - współczynnik pokazuje, jaki jest konkretny wpływ cechy jednoczynnikowej na charakterystykę wynikową, przy ustalaniu wpływu wszystkich innych czynników na określonym poziomie, tj. waga właściwa wpływu wolumenu sprzedaży usług dla osób prawnych (X2) na wielkość zysku (wskaźnik resultatywny) wynosi 72,6% (Δ2 = 0,726369), a specyficzny wpływ zysku netto (X1) na zysk wynosi 27,3% (Δ1 = 0,273631) .
Wykorzystując równanie regresji wielokrotnej z czynnikami istotnymi statystycznie, obliczymy prognozę zysku charakteryzującą wyniki przedsiębiorstwa, wykorzystując możliwości analizy trendów (patrz tabela 2).
Tabela 2
Wyniki analizy trendów charakterystyk czynnikowych

Na podstawie uzyskanych danych obliczamy prognozę punktową Y.
X1 = 1,3737 t - 20,029 t + 294,38, X2 = 2,099 t - 16,372 t + 368,2.
Aby wyznaczyć prognozę charakterystyk czynnikowych, otrzymujemy:
Х1progn =1,3737,21,21-20,029,21+294,38=479,5727 (tysiąc rubli);
Prognoza X2 = 2099,21,21- -16 372,21+368,2 = 950,047 (tysiące rubli).
Aby określić prognozę wydajności pracowników:
Yprogn = 0,871179777.Х1progn + +0,919808093.Х2progn+152,4197205 = =1444,07468 (tysiąc rubli)
Aby wyznaczyć przedziałową prognozę efektywnej pracy pracownika (Y), obliczamy szerokość przedziału ufności ze wzoru:
![]()
Podstawmy pośrednie wyniki obliczeń i otrzymajmy:
U(k)=80,509.2.1098*ROOT(1+0,05+((1444-855)*(1444-855))/3089500)= =183,1231 (tysiąc rubli).
Zatem prognozowana wartość zysku spółki Ypregn = 1444,07468 będzie mieściła się w przedziale
Górna granica wynosi 1444,07468 + 183,1231= 1627,2 i
Dolna granica wynosi 1444,07468 - 183,1231 = 1261 (tysiąc rubli).
Na podstawie wyników badania można wyciągnąć następujące wnioski:
Dokonano oceny pracy indywidualnego pracownika spółki Avtokholod LLC, której główna działalność polega na sprzedaży i montażu dodatkowego wyposażenia pojazdów użytkowych;
Skonstruowano równanie regresji wielokrotnej, aby scharakteryzować zależność wyników pracownika od szeregu czynników;
Prognozowana wartość zysku spółki, obliczona za pomocą równania regresji wielokrotnej, będzie mieścić się w przedziale 1261 tysięcy rubli. do 1627 tysięcy rubli;
Równanie to uznano za istotne statystycznie według kryterium Fishera i charakteryzuje się dość wysoką jakością, dlatego też wyniki obliczeń można uznać za rzetelne i wiarygodne.
Aby zwiększyć efektywność zarówno firmy, jak i jej pracowników, konieczne jest wdrożenie zrównoważonej i zrównoważonej polityki promocji towarów i usług firmy na rynku regionalnym, rozszerzenie badań marketingowych o promocję usług, wprowadzenie innowacyjnych metod prowadzenia działalności gospodarczej z wykorzystaniem nowoczesnych technologii informatycznych oraz metody modelowania i analityki biznesowej działalności przedsiębiorstw.
Link bibliograficzny
Carkow A.O., Gusarova O.M. WYKORZYSTANIE NARZĘDZI MATEMATYCZNO-STATYSTYCZNYCH EKONOMETRII W OCENIE EFEKTYWNOŚCI PRACOWNIKÓW // Międzynarodowy Studencki Biuletyn Naukowy. – 2018 r. – nr 4-6.;Adres URL: http://eduherald.ru/ru/article/view?id=19011 (data dostępu: 25 listopada 2019 r.). Zwracamy uwagę na czasopisma wydawane przez wydawnictwo „Akademia Nauk Przyrodniczych”
Ekonometria to dyscyplina, która łączy w sobie zestaw wyników teoretycznych, metod i technik, które pozwalają, w oparciu o teorię ekonomii, statystykę gospodarczą oraz narzędzia matematyczne i statystyczne, uzyskać ilościowy wyraz wzorców jakościowych. Zajęcia z ekonometrii mają na celu naukę różnych sposobów wyrażania zależności i wzorców poprzez modele ekonometryczne i metody badania ich adekwatności na podstawie danych obserwacyjnych. Podejście ekonometryczne różni się od podejścia matematyczno-statystycznego uwagą, jaką przykłada się do kwestii zgodności wybranego modelu z przedmiotem badań oraz rozważeniem przyczyn prowadzących do konieczności rewizji modelu w oparciu o dokładniejszą system idei. Ekonometria zajmuje się zasadniczo wnioskowaniem statystycznym, tj. wykorzystanie przykładowych informacji w celu uzyskania pewnego wyobrażenia o właściwościach populacji. Najpopularniejszymi modelami ekonometrycznymi są funkcje produkcji oraz modele opisane układem równań równoczesnych. Przyjrzyjmy się im krótko.
Funkcje produkcyjne
Funkcja produkcji to model matematyczny charakteryzujący zależność wielkości produkcji od wielkości kosztów pracy i materiałów. Model można zbudować zarówno dla pojedynczej firmy i branży, jak i dla całej gospodarki narodowej. Rozważmy funkcję produkcji, która zawiera dwa czynniki produkcji - koszty kapitału K i koszty pracy L, które określają wielkość produkcji Q. Następnie możemy napisać
Dany poziom produkcji można osiągnąć stosując różne kombinacje nakładów kapitału i pracy. Krzywe opisane warunkami j(K, L) = const nazywane są izokwantami. Zwykle przyjmuje się, że wraz ze wzrostem wartości jednej ze zmiennych niezależnych maleje krańcowa stopa substytucji danego czynnika produkcji. Zatem przy zachowaniu stałego wolumenu produkcji, oszczędności jednego rodzaju kosztów związane ze wzrostem kosztów innego czynnika stopniowo maleją. Na przykładzie funkcji produkcji Cobba-Douglasa rozważmy główne wnioski, jakie można uzyskać na podstawie propozycji tego lub innego rodzaju funkcji produkcji. Funkcja produkcji Cobba-Douglasa, która obejmuje dwa czynniki produkcji, ma postać
gdzie A, α, β są parametrami modelu. Wartość A zależy od jednostek miary Q, K i L, a także od efektywności procesu produkcyjnego.
Dla ustalonych wartości K i L funkcja Q charakteryzująca się większą wartością parametru A ma większą wartość, dlatego proces produkcyjny opisany taką funkcją jest bardziej efektywny. Opisana funkcja produkcji jest jednoznaczna i ciągła (dla dodatnich K i L). Parametry α i β nazywane są współczynnikami sprężystości. Pokazują, o jaką wielkość Q zmieni się średnio, jeśli α lub β wzrośnie o 1\%.
Rozważmy zachowanie funkcji Q przy zmianie skali produkcji. Załóżmy, że koszty każdego czynnika produkcji wzrosły 100%. Następnie nowa wartość funkcji zostanie wyznaczona w następujący sposób:
Ponadto, jeśli α + β = 1, to poziom efektywności nie zależy od skali produkcji. Jeżeli α + β 1 – maleje wraz ze wzrostem skali produkcji. Należy zauważyć, że właściwości te nie zależą od wartości liczbowych K, L funkcji produkcji. Aby określić parametry i rodzaj funkcji produkcji, należy przeprowadzić dodatkowe obserwacje. Z reguły stosuje się dwa rodzaje danych – szeregi dynamiczne (czasowe) i dane z jednoczesnej obserwacji (informacje przestrzenne). Szeregi czasowe wskaźników ekonomicznych charakteryzują zachowanie tej samej firmy w czasie, natomiast dane drugiego typu dotyczą zazwyczaj tego samego momentu, ale różnych firm. W przypadku, gdy badacz dysponuje szeregiem czasowym, np. danymi rocznymi charakteryzującymi działalność tej samej firmy, pojawiają się trudności, jakich nie napotkałby pracując z danymi przestrzennymi. Tym samym ceny względne zmieniają się w czasie, a co za tym idzie, zmienia się także optymalna kombinacja kosztów poszczególnych czynników produkcji. Ponadto poziom zarządzania administracyjnego zmienia się w czasie. Jednak główne problemy przy stosowaniu szeregów czasowych generują konsekwencje postępu technicznego, w wyniku którego zmieniają się stawki kosztów czynników produkcji, stosunki, w jakich mogą się one wzajemnie zastępować, a także parametry wydajności. W rezultacie nie tylko parametry, ale także formy funkcji produkcji mogą zmieniać się w czasie. Korektę na postęp technologiczny można wprowadzić wykorzystując pewien trend czasowy zawarty w funkcji produkcji. Następnie
Funkcja produkcji Cobba-Douglasa, biorąc pod uwagę postęp techniczny, ma postać
W wyrażeniu tym parametr θ, którym charakteryzuje się postęp techniczny, wskazuje, że wielkość produkcji wzrasta rocznie o θ procent, niezależnie od zmian kosztów czynników produkcji, a w szczególności wielkości nowych inwestycji. Ta forma postępu technicznego, niezwiązana z żadnym wkładem pracy ani kapitału, nazywana jest „niematerialnym postępem technicznym”. Jednak takie podejście nie jest do końca realistyczne, gdyż nowe odkrycia nie mogą mieć wpływu na funkcjonowanie starych maszyn, a zwiększanie wolumenu produkcji możliwe jest jedynie poprzez nowe inwestycje. Przy odmiennym podejściu do postępu technicznego dla każdej „grupy wiekowej” kapitału konstruowana jest jej własna funkcja produkcji. W tym przypadku funkcja Cobba-Douglasa będzie miała postać
gdzie Qt(v) to ilość produktów wyprodukowanych w okresie t na sprzęcie oddanym do użytku w okresie v; Lt(v) to koszty pracy w okresie t związane z obsługą urządzeń oddanych do użytku w okresie v, a Kt(v) to środki trwałe oddane do użytku w okresie v i wykorzystane w okresie t. Parametr v w takiej funkcji produkcji odzwierciedla stan postępu technicznego. Następnie dla okresu t konstruowana jest zagregowana funkcja produkcji, która przedstawia zależność całkowitej wielkości produkcji Qt od całkowitych kosztów pracy Lt i kapitału Kt w chwili t. W przypadku wykorzystania informacji przestrzennej do skonstruowania funkcji produkcji, tj. danych dotyczących kilku firm w tym samym momencie, pojawiają się problemy innego rodzaju. Ponieważ wyniki obserwacji odnoszą się do różnych firm, przy ich wykorzystaniu zakłada się, że zachowanie wszystkich firm można opisać za pomocą tej samej funkcji. Dla pomyślnej interpretacji ekonomicznej powstałego modelu pożądane jest, aby wszystkie te firmy należały do tej samej branży. Ponadto uważa się, że mają one w przybliżeniu takie same możliwości produkcyjne i poziomy zarządzania administracyjnego. Omówione powyżej funkcje produkcji miały charakter deterministyczny i nie uwzględniały wpływu zaburzeń losowych właściwych każdemu zjawisku gospodarczemu. Dlatego w każdym równaniu, którego parametry mają być szacowane, konieczne jest wprowadzenie zmiennej losowej e, która będzie odzwierciedlać wpływ na proces produkcji wszystkich tych czynników, które nie są jawnie ujęte w funkcji produkcji. Zatem ogólnie funkcję produkcji Cobba-Douglasa można przedstawić jako
Otrzymaliśmy model regresji potęgowej, oszacowania parametrów A, α i β można znaleźć metodą najmniejszych kwadratów, jedynie stosując transformację logarytmiczną. Następnie mamy i-tą obserwację
gdzie Qi, Ki i Li to odpowiednio wielkość produkcji, koszty kapitału i pracy dla i-tej obserwacji (i = 1, 2, ..., n), a n to wielkość próby, tj. liczba obserwacji wykorzystanych do otrzymania oszacowań ln, oraz - parametry funkcji produkcji. W odniesieniu do εi przyjmuje się zwykle, że są one od siebie niezależne, a εi О N(0, σ). Bazując na rozważaniach apriorycznych, wartości α i β muszą spełniać warunek 0
Stosując tę formę wyrażenia funkcji produkcji, można wyeliminować wpływ wieloliniowości pomiędzy ln K i ln L. Jako przykład przedstawiamy model Cobba-Douglasa uzyskany na podstawie danych dotyczących 180 przedsiębiorstw produkujących odzież wierzchnią:
Wartości testu t dla współczynników regresji równania podano w nawiasach. W tym przypadku wielokrotny współczynnik determinacji i obliczona wartość statystyki testu F, odpowiednio równa r2 = 0,46 i F = 12,7, wskazują na istotność otrzymanego równania. Oszacowania parametrów α i β funkcji Cobba – Douglasa wynoszą = 0,19 i = 0,95 (1 – 0,19 + 0,14). Ponieważ = 1,14 > 1, można założyć, że wraz ze wzrostem skali produkcji następuje pewien wzrost wydajności. Z parametrów modelu wynika także, że przy wzroście kapitału K o 1\% wolumen produkcji wzrasta średnio o 0,19\%, a przy wzroście kosztów pracy L o 1\% wolumen produkcji wzrasta średnio o 0,95%
Układ równoczesnych równań ekonometrycznych
Układ wzajemnie powiązanych tożsamości i równań regresji, w którym zmienne mogą jednocześnie działać jako wypadki w niektórych równaniach, a objaśniające w innych, nazywany jest zwykle układem równań równoczesnych (ekonometrycznych). W tym przypadku w zależnościach mogą występować zmienne związane nie tylko z momentem t, ale także z momentami poprzednimi. Takie zmienne nazywane są opóźnionymi (opóźnionymi). Tożsamości odzwierciedlają funkcjonalną relację zmiennych. Technika szacowania parametrów układu równań ekonometrycznych ma swoją własną charakterystykę. Wynika to z faktu, że w równaniach regresji układu zmienne niezależne i błędy losowe są ze sobą skorelowane. Własności statystyczne i zagadnienia estymacji układów równań liniowych zostały dość dobrze zbadane. Rozważymy model liniowy o następującej postaci:
gdzie i = 1, 2, ..., G; t = 1, 2, ..., n;
yit jest wartością zmiennej endogenicznej (wynikowej) w chwili t;
xit - wartość predefiniowanej zmiennej, tj. zmienna egzogeniczna (objaśniająca) w chwili t lub opóźniona zmienna endogeniczna;
są to zakłócenia losowe o zerowych średnich.
Zbiór równości (53,60) nazywany jest układem równoczesnych równań w postaci strukturalnej. Obecność ograniczeń apriorycznych, związanych np. z faktem, że niektóre współczynniki uznaje się za równe zeru, daje możliwość statystycznej oceny pozostałych. W postaci macierzowej układ równań można przedstawić jako
gdzie B jest macierzą rzędu G x G, składającą się ze współczynników dla bieżących wartości zmiennych endogenicznych;
G jest macierzą rzędu G x K, składającą się ze współczynników zmiennych egzogenicznych.
yt = (y1t,..., yGti)T, xt = (x1t,... xkt)T, εt = (ε1t,... εGt)T - wektory kolumnowe wartości odpowiednio zmiennych endogenicznych i egzogenicznych i błędy losowe. Należy zauważyć, że Mεt = 0; Σ(ε) = MεtεtT = , gdzie En jest macierzą jednostkową. Zatem jeśli Mεt1εt2 = 0 dla t1 ≠ t2 i t1, t2 = 1, 2, ..., n, to błędy losowe są od siebie niezależne. Jeśli wariancja błędu jest stała Mε = 2 i nie zależy od t i xt, oznacza to, że reszty są homoskedastyczne. Warunkiem heteroskedastyczności jest zależność wartości Mε = od t i xt. Mnożąc wszystkie elementy równania (53.61) po lewej stronie przez macierz odwrotną B-1, otrzymujemy zredukowaną postać układu równań równoczesnych:
Spośród układów równań równoczesnych najprostsze są układy rekurencyjne, do szacowania współczynników, dla których można zastosować metodę najmniejszych kwadratów. Układ (53.61) równań równoczesnych nazywa się rekurencyjnym, jeśli spełnione są następujące warunki:
macierz wartości zmiennych endogenicznych
jest dolną macierzą trójkątną, tj. βij = 0 dla j > 1 i βii = 1;
2) błędy losowe są od siebie niezależne, tj. σii > 0, σij = 0 dla i ≠ j, gdzie i, j = 1, 2, ..., G. Wynika z tego, że macierz błędu kowariancji МεtεtT = Σ(ε) jest diagonalna;
3) każde ograniczenie współczynników konstrukcji dotyczy osobnego równania. Procedura estymacji współczynników układu rekurencyjnego metodą najmniejszych kwadratów zastosowana do osobnego równania prowadzi do spójnych estymacji.
Jako przykład rozważmy sytuację, która prowadzi do rekurencyjnego układu równań. Załóżmy, że ceny rynkowe Pt w dniu t zależą od wielkości sprzedaży poprzedniego dnia qt-1, a wielkość zakupów qt w dniu t zależy od ceny produktu w dniu t. Matematycznie układ równań można przedstawić jako
Stosowanie metody najmniejszych kwadratów do otrzymywania estymatorów równań równoczesnych prowadzi do szacunków obciążonych i niespójnych, dlatego jej zakres ogranicza się do układów rekurencyjnych. Do estymacji układów równań równoczesnych najczęściej stosuje się obecnie dwuetapową metodę najmniejszych kwadratów, stosowaną do każdego równania układu z osobna, oraz trójstopniową metodę najmniejszych kwadratów, przeznaczoną do estymacji całego układu jako całości. Istota metody dwuetapowej polega na tym, że do estymacji parametrów równania strukturalnego stosuje się metodę najmniejszych kwadratów dwuetapowo. Daje spójne, choć w ogólnym przypadku obciążone szacunki współczynników równania, jest dość proste z teoretycznego punktu widzenia i wygodne do obliczeń.
Zgodnie z trójetapowym algorytmem najmniejszych kwadratów, do oszacowania współczynników każdego równania strukturalnego początkowo stosuje się dwuetapową metodę najmniejszych kwadratów, a następnie wyznacza się estymację macierzy kowariancji zakłócenia losowego. Następnie stosuje się uogólnioną metodę najmniejszych kwadratów w celu oszacowania współczynników całego układu.
Przykład. Budowa modelu ekonometrycznego światowego rynku ropy naftowej
Oczywiście model musi odzwierciedlać relację pomiędzy trzema głównymi elementami mechanizmu rynkowego – popytem, ceną i podażą (zmiennymi endogenicznymi). Z kolei stan tych elementów w każdym momencie można scharakteryzować za pomocą układu objaśniających zmiennych egzogenicznych.
System obejmuje ogólne wskaźniki gospodarcze i towarowo-rynkowe. Ogólne wskaźniki ekonomiczne odzwierciedlają procesy gospodarcze zachodzące na świecie i w poszczególnych krajach oraz dają wyobrażenie o tle, na którym następuje rozwój rynku. Druga grupa wskaźników odzwierciedla zjawiska charakterystyczne dla rynku ropy. Szczególnie interesujące są wskaźniki, które mają efekt wiodący (opóźnienie) w stosunku do dynamiki zmiennych endogenicznych rynku ropy.
Przy wyborze zmiennych egzogenicznych wzięto pod uwagę, że o stanie rynku ropy naftowej w każdym momencie decydują nie tylko jego czynniki wewnętrzne, ale także stan otoczenia zewnętrznego, tj. ogólna sytuacja gospodarcza całej gospodarki światowej, a przede wszystkim - dynamika cyklu reprodukcyjnego, poziom aktywności gospodarczej w branżach konsumenckich, sytuacja w sferze monetarnej i monetarnej gospodarki.
Ostatnim etapem tworzenia modelu badanego rynku jest jego wdrożenie. Na tym etapie tworzony jest model matematyczny w postaci ogólnej, oceniane są jego parametry, dokonywana jest sensowna interpretacja ekonomiczna oraz wyjaśniane są jego właściwości statystyczne i predykcyjne.
Przy budowie modelu wykorzystano system wskaźników oparty na kwartalnych szeregach czasowych z okresu ostatnich 15 lat, który charakteryzuje główne aspekty rynku ropy naftowej w aspekcie ekonomicznym, czasowym i geograficznym.
Przeprowadzenie analizy korelacji na etapie wstępnego przetwarzania danych pozwoliło zawęzić zakres stosowanych wskaźników (początkowo było ich ponad sto), wybrać do dalszej analizy te, które odzwierciedlają wpływ głównych czynników na rynku ropy naftowej i są najściślej powiązane z dynamiką wskaźników rynkowych. Jednocześnie rozwiązano także problem eliminacji wpływu wielowspółliniowości.
Model został zbudowany w oparciu o założenie, że wielkość popytu odgrywa bardziej aktywną rolę niż czynniki podaży i ceny. Model rekurencyjny zawiera równania regresji liniowej dla następujących zmiennych endogenicznych w chwili t:
y1,t – eksport ropy z krajów OPEC;
у2,t – wydobycie ropy w krajach OPEC;
y3,t to cena lekkiej ropy arabskiej.
W modelu uwzględniono predefiniowane zmienne:
y3,t-1 – cena lekkiej ropy arabskiej z opóźnieniem 1 kwartału;
x6,t – dostawy ropy naftowej do rafinacji do Japonii;
x7,t-1 - dostawy ropy do rafinacji do USA w czasie t-1;
x9,t – komercyjne zasoby ropy naftowej w Europie Zachodniej;
x10,t-1 – komercyjne zasoby ropy naftowej w USA z opóźnieniem 1 kwartału;
x12,t – eksport ropy naftowej z byłego ZSRR do krajów rozwiniętych;
x20,t-2 to wskaźnik cen eksportowych ONZ dla paliw z opóźnieniem 2 kwartałów, a x20,t-3 - 3 kwartały;
y1,t/y2,t to wskaźnik uwzględniający brak równowagi na rynku ropy naftowej w chwili t.
Model ekonometryczny rynku ropy naftowej przedstawia się następująco:
Analiza charakterystyk statystycznych modelu wykazała, że generalnie dobrze opisuje on rynek ropy naftowej: wszystkie równania są istotne, wyjaśniają od 67 do 92% wariancji zmiennych endogenicznych i charakteryzują się niewielkimi odchyleniami obliczonych wartości zmiennych endogenicznych od rzeczywistych. Istotność współczynników modelu sprawdzono za pomocą testu t. Obliczone wartości tj podano w nawiasach pod odpowiednimi współczynnikami.
Zbudowany model pozwala na analizę różnych sytuacji w rozwoju rynku ropy.
Pytania bezpieczeństwa
Co charakteryzuje współczynniki korelacji parowej, częściowej i wielokrotnej? Sformułuj ich główne właściwości.
Jakie problemy rozwiązują metody analizy regresji?
Jakie są negatywne konsekwencje wielowspółliniowości i jak pozbyć się tego negatywnego zjawiska?
Jakie jest zadanie analizy składowej, jak interpretować składowe główne i określić ich udział w wariancji całkowitej?
Jakie problemy rozwiązuje analiza skupień? Jakie są cechy hierarchicznych procedur klastrowych?